
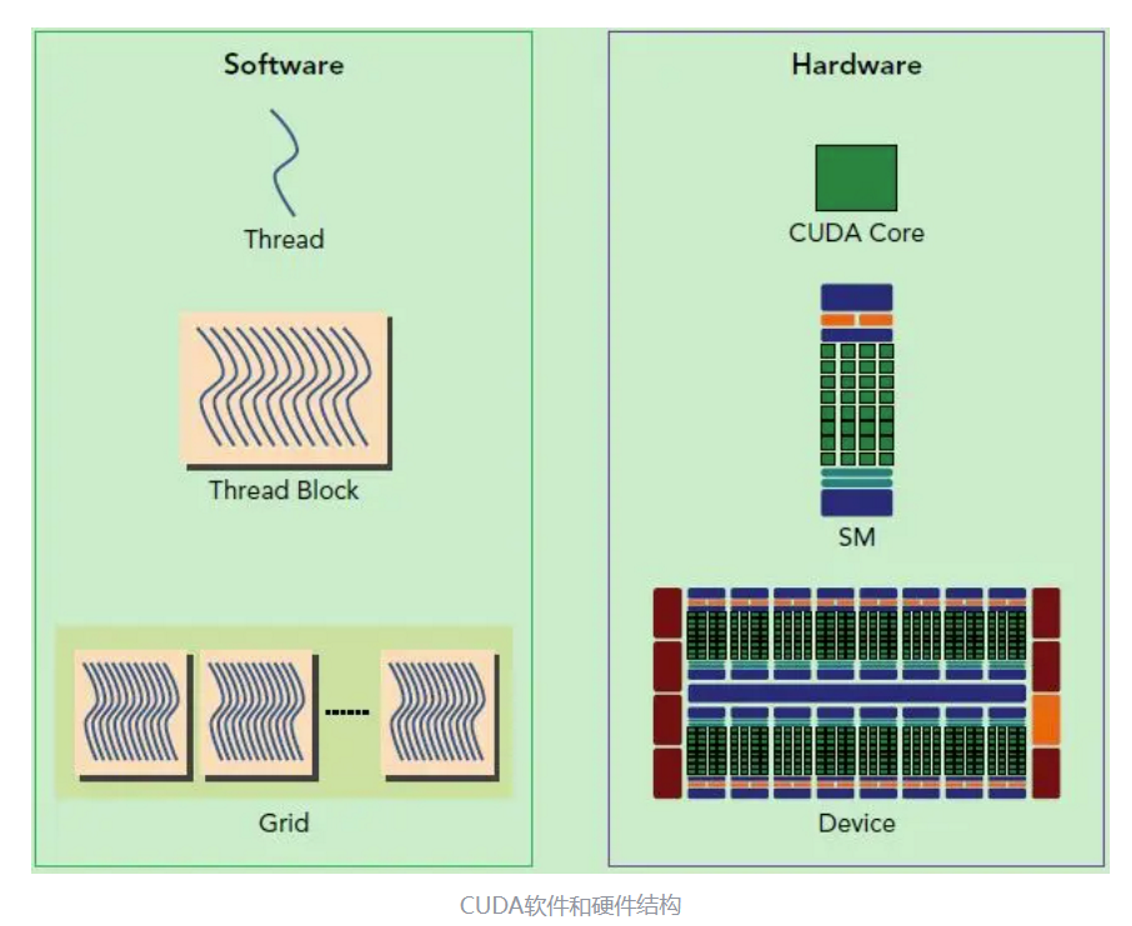
总体架构
硬件设计
SP:Stream Processor即CUDA core,GPU的基本处理单元
SM:Stream Multiprocessor,并行处理单元由多个sp组成,包含SFU,共享内存,寄存器,warp schedule等资源,可执行多个Block
Device Kernel:GPU内核,不同架构GPU内核数存在不同
软件设计
Thread:线程,程序指令的基本执行单元
Block:多个thread组成,GPU上独立的执行单元,执行在一个SM上,内部线程可同步
Grid:多个block组成,执行在一个GPU kernel上
GPC-TPC-SM架构
AD102: The full AD102 GPU includes 12 Graphics Processing Clusters (GPCs), 72 Texture Processing Clusters (TPCs), 144 Streaming Multiprocessors (SMs), and a 384-bit memory interface with 12 32-bit memory controllers.
以GP102架构为例,一个Device由12组GPC构成
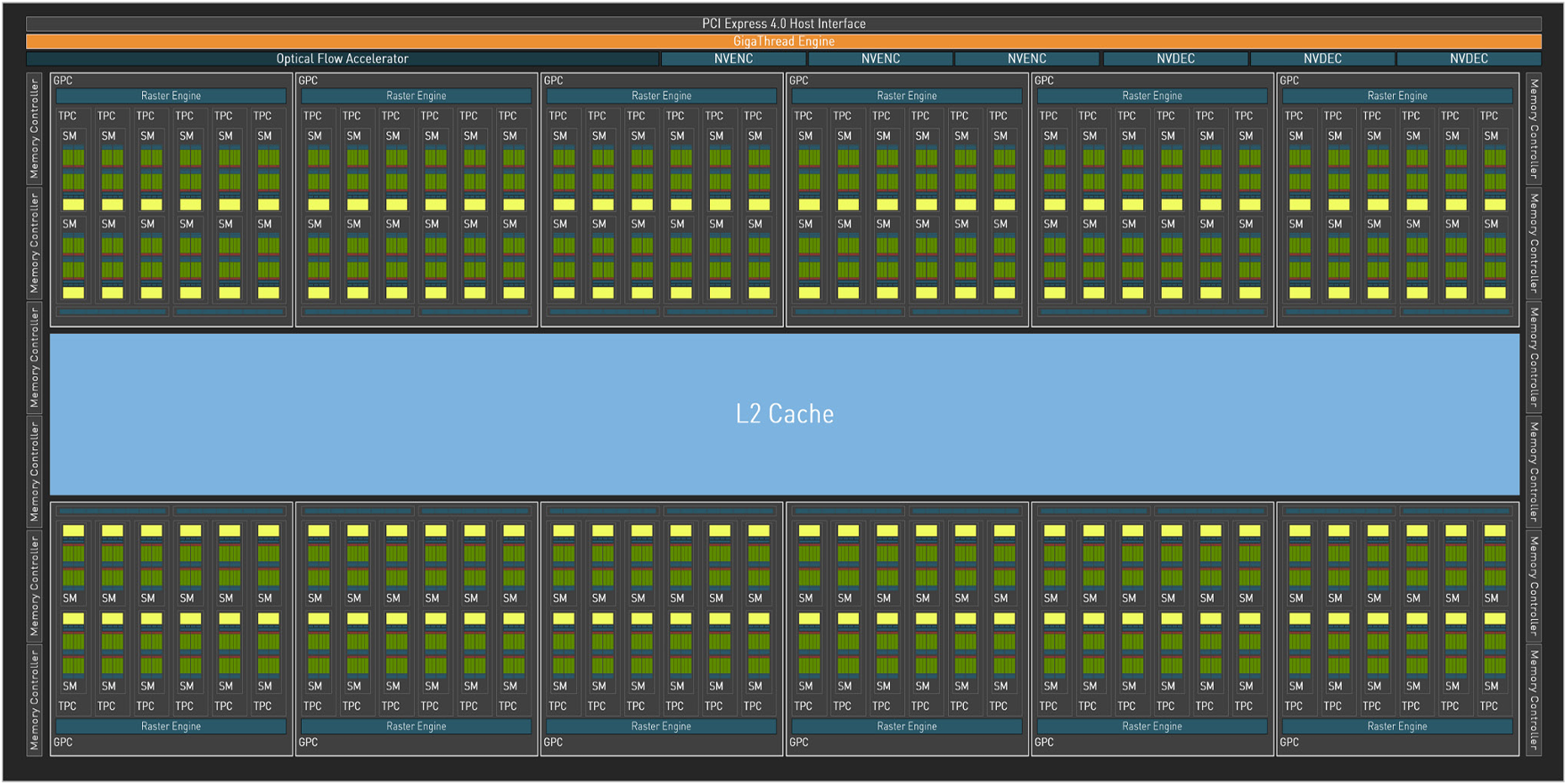
每组GPC由6个TPC构成,每个TPC内含2个SM 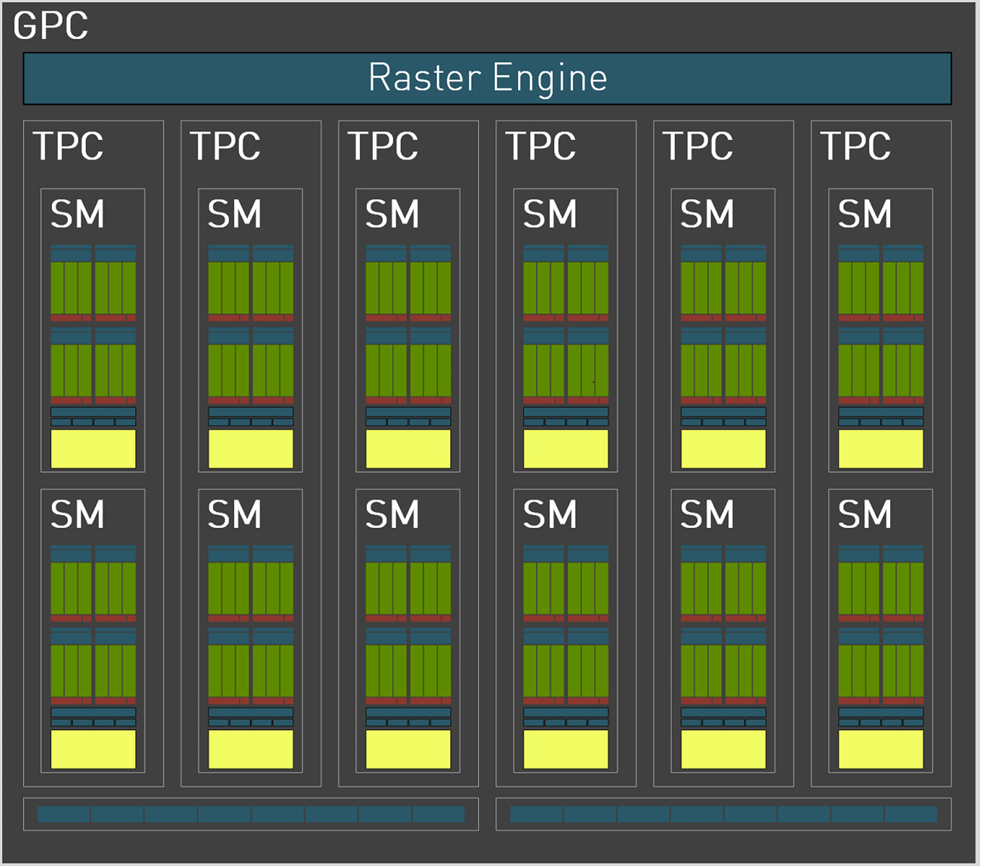
每个SM包含128个CUDA core,总核心数=12x6x2x128 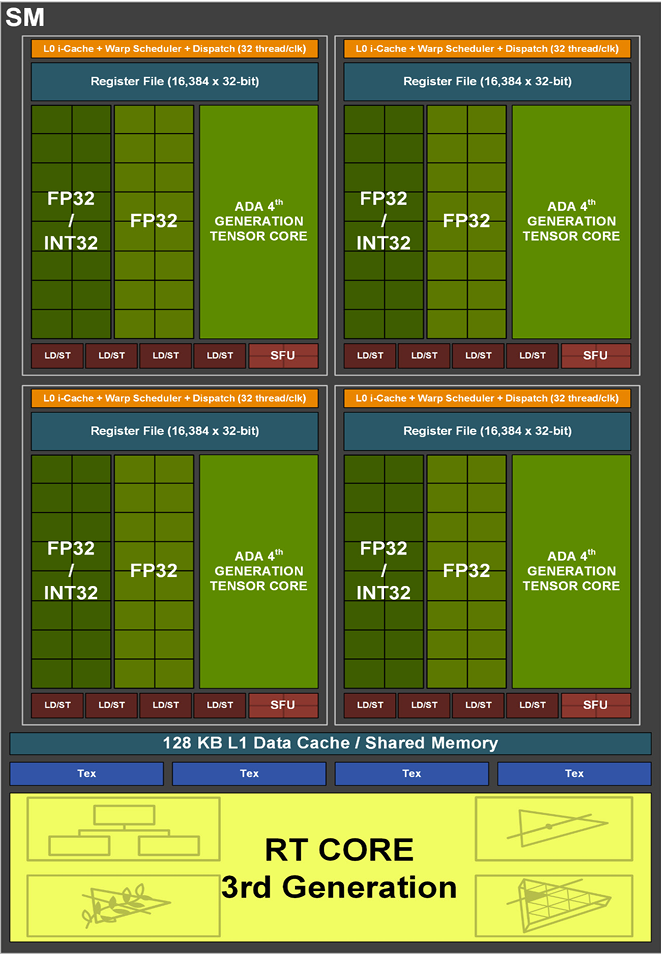
软硬件关联
Grid:一个grid执行在一个GPU Kernel上
Block:多个block由SM调度执行,block数取决于SM资源(寄存器、shared memory等)及block内线程数、单线程占用寄存器数。
Warp:block内线程由warp组织,通常32个thread组成一个warp,warp是SM调度的基本单元。同一个warp内严格串行,无需同步。
当一个block获得到足够的资源时,就成为active block。block中的warp就称为active warp。active warp又可以被分为下面三类:
- Selected warp:一个被选中的warp称为Selected warp
- Stalled warp:没准备好要被执行的warp
- Eligible warp:没被选中,但是已经做好准备被执行的warp
warp适合执行需要满足下面两个条件:
- 32个CUDA core有空
- 所有当前指令的参数都准备就绪
Thread:线程,最小执行单元,发送到一个SP上执行。
Block&SM
引述远古CUDA架构设计:
CUDA 的 device 實際在執行的時候,會以 Block 為單位,把一個個的 block 分配給 SM 進行運算;而 block 中的 thread,又會以「warp」為單位,把 thread 來做分組計算。目前 CUDA 的 warp 大小都是 32,也就是 32 個 thread 會被群組成一個 warp 來一起執行;同一個 warp 裡的 thread,會以不同的資料,執行同樣的指令。基本上 warp 分組的動作是由 SM 自動進行的,會以連續的方式來做分組。
Block通过Warp组织块内线程,SM通过warp schedule管理warp,每次选取一个eligible warp发射指令,warp指令需等待时则取下一个warp继续执行,呈现SM层面的宏观并行。所选取的warp可以是同一个block或不同block的。
why block
引述NV社区问答:
为什么要有一个中间的层次block呢?这是因为CUDA通过这个概念,提供了细粒度的通信手段,因为block是加载在SM上运行的,所以可以利用SM提供的shared memory和__syncthreads()功能实现线程同步和通信,这带来了很多好处。
而block之间,除了结束kernel之外是无法同步的,一般也不保证运行先后顺序,这是因为CUDA程序要保证在不同规模(不同SM数量)的GPU上都可以运行,必须具备规模的可扩展性,因此___block之间不能有依赖___。